
Понятие Proof-of-work – «доказательство (проделанной) работы» – впервые появилось в работе “Pricing via Processing or Combatting Junk Mail” в 1993 г. И хотя в данной статье такого термина еще нет (появится через 6 лет), мы будем называть его именно так (PoW для краткости). Какую же идею предложили Cynthia Dwork и Moni Naor в своей работе?

«Чтобы получить доступ к общему ресурсу, пользователь должен вычислить некоторую функцию: достаточно сложную, но посильную; так можно защитить ресурс от злоупотребления»
Если провести аналогию, Рыбнадзор обязывает Джереми Уэйда немного потрудиться, чтобы получить доступ к местному пруду – например, посадить несколько деревьев и прислать фото саженцев. При этом Джереми должен быть в состоянии с ней справиться за разумное время: до того, как все рыбы будут отравлены выбрасываемыми в окружающую среду веществами. Но, с другой стороны, работа не должна быть элементарной, иначе толпы рыбаков быстро опустошат весь пруд.
В цифровом мире придумать пример подобной работы на самом деле не так тривиально.
Сервер может, например, предложить пользователю умножить два случайных длинных числа и потом проверить результат. Проблема очевидна: проверка не сильно быстрее самой работы, т.е. сервер просто не справится с большим потоком клиентов.
Следующая попытка: сервер придумывает два длинных простых числа, умножает их и сообщает результат пользователю. Последний должен выполнить разложение на множители, это уже посложнее. Здесь есть нюансы, но в целом схема стала лучше: коэффициент «время работы / время проверки» сильно вырос. Это и есть основное требование, сформулированное в статье:
«Вычисление функции на заданном входе должно быть гораздо сложнее, чем проверка результата»
Помимо этого требовалось, чтобы функция не была амортизируемой (читай – не распараллеливалась), т.е. чтобы время решения нескольких задач было пропорционально их количеству (Если Джереми хочет получить двойную квоту на ловлю рыбы, то и трудиться надо в два раза дольше: вчерашние или чужие фотографии не подойдут).
В качестве примера таких функций было (среди прочих) предложено вычисление квадратного корня по модулю простого числа P: здесь мы имеем log(P) умножений на решение и лишь одно умножение для проверки). Входное значение может выдаваться как сервером (сгенерировать x, выдать x^2), так и выбираться автономно: выбрать x, найти sqrt(hash(x)). В последнем случае нужен небольшой напильник: не всякий элемент в Z_p является квадратом. Но это уже мелочи.
В течение следующих лет появлялись и другие работы с ключевыми словами proof-of-work. Среди них следует отметить две:
- Проект Hashcash от Адама Бэка, посвященный той же защите от спама. Задача формулировалась так: «Найти такое значение x, что хэш SHA(x) содержал бы N старших нулевых бит». То есть фактически работа сводилась к хэшированию одних и тех же данных (письма) с перебираемой частью. Поскольку используется стойкая необратимая хэш-функция, то ничего лучше перебора нет; и средний объем работы экспоненциально зависит от N. Очень простая схема, да?
- "Moderately hard, memory-bound functions". Ключевое слово здесь – memory-bound («ограниченные памятью»). К началу нулевых стало заметно, что разница между low-end и high-end процессорами слишком велика для PoW-задач, чтобы стричь всех под одну гребенку. Предложенный в статье алгоритм был первым, который задействовал в вычислениях относительно большие (мегабайты) объемы памяти. Узким местом в таких схемах становилась не скорость процессора, а задержка при обмене данных с RAM или сам объем требуемой памяти, которые варьировались в компьютерах в более узких пределах. Одним из таких алгоритмов и был scrypt, но об этом позже.
Неверным было бы сказать, что Сатоши был первым, кто придумал использовать PoW для электронных денег. Идея под названием “reusable proof-of-work” витала в криптоанархических кругах (и даже была частично реализована), но в своем изначальном виде популярности не приобрела.
Концепция RPoW от Хэла Финни предполагала, что сами «токены-доказательства» являлись бы самостоятельной ценностью (монетами), в то время как в Bitcoin механизм PoW был использован как средство достижения распределенного консенсуса (единого мнения о том, какую версию блокчейна считать верной). И в этом была ключевая идея Bitcoin, которая «выстрелила».
В качестве proof-of-work схемы была выбрана идея Hashcash, а вычисляемой функцией стала SHA-256 – самая популярная хэш-функция в тот момент (2008 г). Скорее всего, именно простота Hashcash и «стандартность» SHA-256 оказались решающими факторами. Сатоши добавил к Hashcash механизм изменяющейся сложности (уменьшать-увеличивать N – требуемое число нулей – в зависимости от суммарной мощности участников) и этим, казалось бы, обеспечил всем безоблачное децентрализованное будущее. Но потом случилось то, что случилось: GPU, FPGA, ASIC и даже облачный дентрализованный майнинг.
Нет единого мнения о том, «предвидел ли Сатоши» все это безобразие или нет, но факт такой: уже в сентябре 2011 появилась первая криптовалюта с принципиально другой функцией PoW: Tenebrix использовал scrypt вместо SHA-256 .
Итак, зачем же вместо таких полезных и важных изменений в коде Bitcoin, как, например, общее число монет, стали менять критически важный элемент – алгоритм консенсуса? Повод очевидный: в 2011 г уже вовсю работали GPU-фермы, собирались предзаказы на FPGA и потенциально маячили ASIC’и – т.е. вклад обычного CPU-юзера был практически нулевой. Но в чем причина?
Можно объяснить, конечно, все обычной обидой или желанием «срубить бабла»: до Tenebrix уже были и форки, и премайны, и pump’n’dump. Но аргументы сторонников “ASIC-resistance” функций вполне разумны:
- Популяризация.
Поскольку каждый компьютер (в теории) дает примерно одинаковый хэшрейт, то большее число людей будет участвовать в майнинге, пусть даже и в фоновом режиме. Сотни миллионов офисных машин, слегка нагрузив свой CPU, будут вносить вклад в защиту сети, получать за это монетки, которые потом пойдут в оборот. - Децентрализация.
Здесь даже два аспекта: во-первых, производители железа. Большинство ASIC’ов производится на нескольких заводах в Китае, а компетенцией в производстве тоже обладают единицы. Другое дело – ПК общего назначения. Во-вторых, географическое расположение майнеров. Если не принимать в расчет пулы, то универсальный CPU-friendly алгоритм имеет больший ареал распространения: кто угодно может позволить себе запустить майнер. - Дороговизна атаки 51%.
Конечно, всегда можно спроектировать специальный девайс, решающий определенную задачу эффективнее (по времени или по энергозатратам), чем обычный ПК. Другой вопрос: а сколько будет стоить reseach+development такого устройства, какие масштабы производства должны быть, чтобы весь проект был экономически выгоден и т.д.? Считается, что в любом случае это будет дороже, чем в текущих реалиях Bitcoin. (Имеется в виду не абсолютная оценка стоимости атаки: а относительно, грубо говоря, уровня зрелости всей сети. Так, скажем, сеть даже с самым супер-крутым ASIC-proof алгоритмом можно дешево атаковать, если в ней пока майнит только два десятка машин.)
Конечно, на каждый пункт всегда можно что-то возразить, но я лишь хочу показать, что при выборе PoW-функции есть смысл думать над ее «ASIC-защищенностью». На самом деле, об этом аспекте неявно было сказано в самой первой статье! Именно неамортизируемость функции можно с натяжкой считать ASIC-защищенностью.
Теперь немного технических подробностей о том, как работает алгоритм scrypt, легший в основу Tenebrix, а в дальнейшем и Litecoin (который, как вы, возможно, знаете, стал второй по популярности криптовалютой).
Строго говоря, scrypt – не криптографическая хэш-функция, а функция формирования ключа (key derivation function, KDF). Такие алгоритмы используются для ровно там, где вы и подумали: для получения секретного ключа из каких-то данных (парольной фразы, случайных бит и т.д.). Среди примеров можно также назвать PBKDF2 и bcrypt.
Основная задача KDF – затруднить генерацию конечного ключа: несильно, чтобы можно было использовать в прикладных задачах, но настолько, чтобы предотвратить случаи злоумышленного использования (например, массовый перебор паролей). Формулировка очень напоминает кое-что, не так ли? Неудивительно, что они встретились – как Зита и Гита – PoW и KDF.
Схема работы scrypt
Первый слой:
- Входные данные пропускаются через PBKDF2
- Hазбиваются на p блоков, каждый обрабатывается функцией SMix,
- Результат снова склеивается и пропускается через PBKDF2.
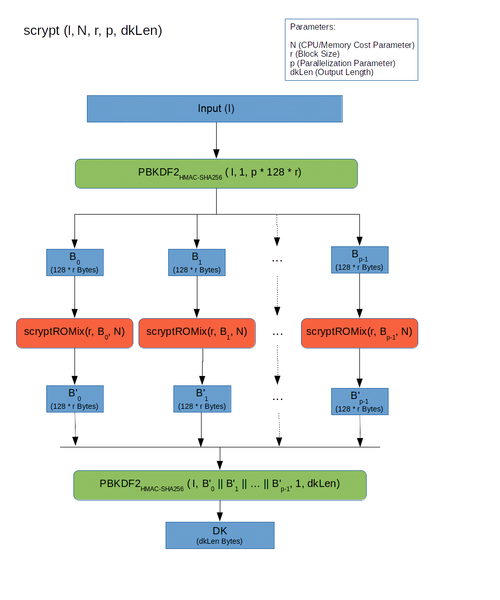
Заметьте, что здесь каждый из p блоков может обрабатываться отдельно. Т.е. scrypt в теории допускает возможность распараллеливания (но по умолчанию p=1)
Второй слой:
- Входной блок последовательным применением псевдослучайной функции BlockMix расширяется до массива из N блоков.
- Блок X, полученный из последнего элемента, интерпретируется как целое число j, и из массива читается элемент Vj
- X = BlockMix(X xor Vj)
- Шаги 2-3 повторяются N раз
- Результатом является текущее значение блока X
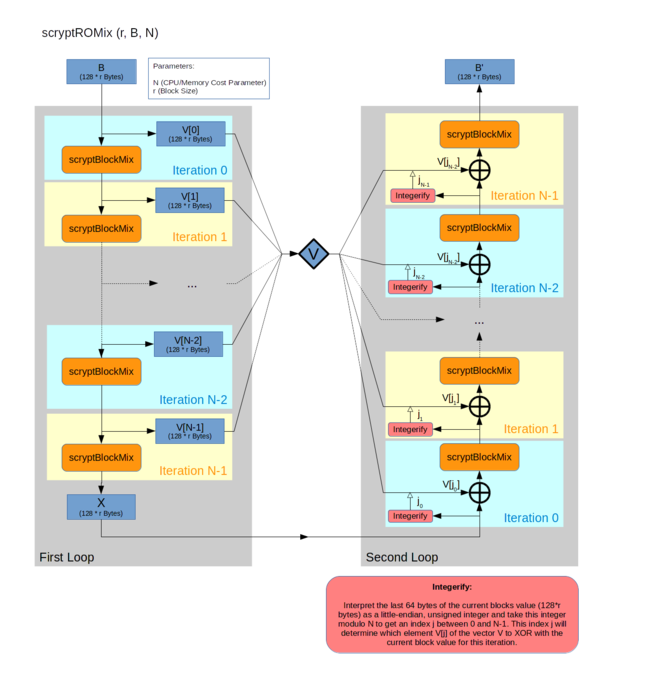
Тут происходит самое интересное. Чем большее значение N мы выбираем, тем больше памяти требует алгоритм. И хотя на каждом шаге 2-3 нам требуется лишь один элемент из всего массива, мы не можем освободить память до шага 5: ведь этот элемент выбирается псевдослучайно, в зависимости от последнего результата! Таким образом, если сама функция BlockMix (см. ниже) выполняется быстро, узким местом становятся задержки (latency).
Третий слой:
- Вход разбивается на 2r блоков
- Каждый блок xor-ится с предыдущим и хэшируется функцией H
- Результат выдается в переставленном порядке
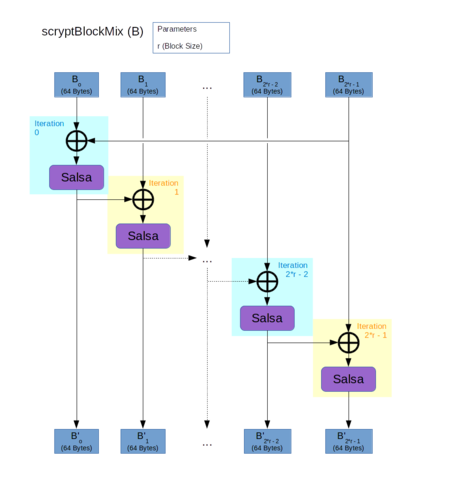
В качестве функции H используется Salsa20/8. Да, это не хэш-функция, а потоковый шифр. Но для целей scrypt не требуется устойчивость к коллизиям, а только быстрый и псевдослучайный результат, поэтому Salsa очень даже подходила. По умолчанию scrypt предлагает r=8, однако в криптовалюте выбрали r=1 (скорее всего, для скорости). О последствиях мы напишем позже.
Подробности касательно выбра тех или иных параметров в алгоритме можно найти тут.
Параметры scrypt для Tenebrix были выбраны так, чтобы общий объем требуемой памяти укладывался в 128 КБ: так можно поместиться в L2 кэш процессора. А по умолчанию использовалось 16 МБ! Эксперимент оказался более чем удачным: позабытые было на обочине прогресса CPU-майнеры быстро включились в игру. Подавляющее большинство новых форков уже отпочковывалось от Litecoin, унаследуя scrypt вместо SHA256.
Как ни странно, пользователей не смутил тот факт, что 128 КБ параметры оказались вполне по зубам и видеокартам. Оптимизированный GPU-майнер появился спустя несколько месяцев и давал в среднем десятикратный прирост эффективности. «Зато не в 100 раз, как в Bitcoin!» — говорили они, — «Зато не в 1000 раз!» Увеличение соотношения GPU/CPU-мощностей (вытесняемых из Bitcoin новыми ASIC’ами) было не таким резким, наверное, потому, что компенсировалось бумов форков: новая scrypt-криптовалюта появлялась едва ли не раз в неделю, отягивая на себя новые мощности.
И все же понимание того, что scrypt далеко не идеальная PoW функция, появилось даже раньше, чем анонс scrypt-ASIC. Головокружение от успехов прошло, культ Сатоши немного пошел на убыль, и идеи для новых PoW-кандидатов стали появляться как после дождя.
Комментарии:
asessor
#
Алгоритм майнинга PoW всем хорош, если он защищен от возможности добывать криптовалюту без использования ASIC-майнеров. Децентрализация и отличная защита от атаки 51 этому коину гарантирована.
сб, 09/29/2018 - 00:54