
Давайте создадим агентов для торговых сделок с криптовалютой, используя глубокое обучение с подкреплением (один из способов машинного обучения, в ходе которого испытуемая система (агент) обучается, взаимодействуя с некоторой средой).

Наша задача в этой статье – создать агентов с помощью системы машинного обучения, которые научатся зарабатывать деньги на торговых операциях с биткоином. В этой обучающей статье мы будем использовать OpenAI gym (бесплатный инструмент компании OpenAI для разработки и тренировки ИИ-ботов с помощью игр и алгоритмических испытаний) и PPO-агент из библиотеки Stable-Baselines, улучшенный вариант алгоритма машинного обучения на базе OpenAI Baselines.
Большое спасибо OpenAI и DeepMind за программное обеспечение с открытым исходным кодом, которое они предоставляли исследователям алгоритмов глубокого обучения в течение последних нескольких лет. Если вы еще не видели, какие крутые штуки они сделали помощью таких технологий, как AlphaGo, OpenAI Five и AlphaStar, то, скорее всего, в течение последнего года вы жили в пещере, - обязательно ознакомьтесь с ними.
Хотя то, что мы собираемся сделать, не настолько впечатляюще, тем не менее, наладить выгодные торговые операции с биткоином на ежедневной основе – не такая уж и легкая задача. Однако, как сказал однажды Теодор Рузвельт,
Ничто стоящее в этой жизни не дается легко.
Так что вместо того, чтобы самим учиться торговать... давайте сделаем робота, который будет делать это вместо нас.
План

- Создание тренировочной среды для обучения нашего агента.
- Простая, но при этом утонченная визуализация этой среды.
- Обучение нашего агента стратегии прибыльной торговли.
Если вы еще не в курсе, как с нуля создать тренировочную среду или как визуализировать эту среду, я буквально на днях опубликовал статьи по обеим этим темам. Можете пока сделать перерыв и почитать их, прежде чем мы пойдем дальше.
Начало работы
В этой статье мы будем использовать набор данных Kaggle, созданный компанией Zielak. Доступ к файлу данных .csv вы также сможете получить в моем хранилище на GitHub, если вам нужен будет код для дальнейшего использования. Итак, давайте начнем.
Сначала скачиваем все необходимые библиотеки и смотрим, что все недостающее есть в наличии.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessingТеперь давайте создадим наш класс среды. Нам потребуется фрейм данных pandas, а также initial_balance (на усмотрение) и alookback_window_size, которые будут показывать, сколько временных шагов в прошлом проходил агент на каждом этапе. По умолчанию значение комиссии за сделку составляет 0,075%, что соответствует текущей ставке Bitmex, а serialparameter соответствует false, что означает, что прохождение нашего фрейма данных по умолчанию будет осуществляться в случайных срезах.
Мы также вызываем функции dropna()и reset_index() во фрейме данных, чтобы сначала удалить все строки со значениями NaN, а затем сбросить индекс фрейма, так как мы удалили данные.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10,
lookback_window_size + 1), dtype=np.float16)Наш action_space здесь представлен как дискретный набор из 3 опций (покупка, продажа или удержание) и еще один дискретный набор из 10 сумм (1/10, 2/10, 3/10 и т.д.). Когда будет выбрано действие buy (купить), мы купим BTC на сумму amount * self.balance. Для продажи (действие sell) мы продадим BTC на сумму amount * self.btc_held. Естественно, при выборе действия hold (удержание) сумма будет игнорироваться и ничего не будет делаться.
Наш observation_space определяется как непрерывный набор плавающих значений от 0 до 1, с формой(10, lookback_window_size + 1). Приписка + 1 необходима для учета текущего шага времени.
Для каждого временного шага в окне будут отображаться значения OHCLV, наш чистый капитал, количество купленных или проданных BTC и общая сумма в долларах США, которую мы потратили или получили от этих BTC.
Далее нам нужно писать наш метод reset для инициализации среды.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()Здесь мы используем как self._reset_session, так и self._next_observation, которые мы еще не определили. Давайте сделаем это.
Торговые сессии
Важной частью нашей среды является концепция торговой сессии. Если бы нам пришлось развернуть этого агента в «дикой» среде, то, скорее всего, мы бы никогда не смогли запустить его дольше чем на пару месяцев. По этой причине мы ограничим количество непрерывных фреймов в self.df, которые наш агент будет видеть подряд.
В нашем _reset_session методе мы сначала установим значение current_step на 0. Затем мы зададим для steps_left случайное число от 1 до MAX_TRADING_SESSION, которое мы укажем в верхней части файла.
MAX_TRADING_SESSION = 100000 # ~2 months
Затем, при последовательном прохождении фрейма, мы настроим фрейм целиком, который нужно будет пройти, в противном случае мы зададим для frame_start случайную точку внутри self.df и создадим новый фрейм данных под названием active_df, который является просто срезом (фрагментом) self.df от frame_start до frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(
self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start -
self.lookback_window_size:self.frame_start + self.steps_left]Одним из важных побочных эффектов прохождения фрейма данных в случайных срезах является то, что наш агент будет иметь гораздо более уникальные данные для работы при обучении в течение длительного периода времени. Например, если бы мы когда-либо прошли фрейм данных последовательным образом (т. е. в порядке от 0 до len(df)), то у нас всегда было бы столько уникальных точек данных, сколько бы имелось в нашем фрейме данных. Наше пространство для наблюдения способно было бы принимать только дискретное число состояний на каждом временном шаге.
Однако при случайном прохождении фрагментов фрейма данных мы, по сути, создаем больше уникальных точек данных, создавая более интересные комбинации баланса счета, сделок и ранее наблюдаемых ценовых действий для каждого временного шага в нашем исходном наборе данных. Поясню на примере.
На временном шаге 10 после переустановки последовательности (среды) наш агент всегда будет находиться на том же самом временном этапе во фрейме данных и у будет 3 варианта для выбора, который нужно сделать на каждом временном этапе: покупка, продажа или владение. И для каждого из этих трех вариантов потребуется сделать еще один выбор: 10%, 20%, ... или 100% от возможной суммы. Это означает, что наш агент может испытать любое из состояний (1х3)1 total среди общего числа 1030 возможных уникальных переживаний.
Теперь рассмотрим нашу поделенную на случайные фрагменты (срезы) среду. На временном шаге 10 наш агент смог быть находиться на любом из len(df) временных этапов во фрейме данных. Учитывая одни и те же варианты выбора на каждом временном этапе, это означает, что этот агент может испытать любое из len(df)30 возможных уникальных состояний в течение тех же 10 временных шагов.
Хотя это может добавить довольно много информационного «шума» к большим наборам данных, я считаю, что это должно позволить агенту узнать больше из нашего ограниченного объема данных. Мы по-прежнему будем последовательно просматривать наши тестовые данные, чтобы получить более точное представление о полезности алгоритма для свежих и, казалось бы, «живых» данных.
Жизнь глазами агента
Нередко бывает полезным визуализировать пространство для наблюдения за средой, чтобы получить представление о типах функций, с которыми будет работать ваш агент. Например, вот визуализация нашего пространства для наблюдения, выполненная с помощью OpenCV.
Визуализация пространства для наблюдения за средой с помощью OpenCV
Каждый ряд в изображении представляет собой ряд в нашем пространстве для наблюдения observation_space. Первые 4 ряда красных линий в виде частотных импульсов представляют собой данные OHCL, а паразитные оранжевые и желтые точки непосредственно под ними представляют собой объем. Колеблющаяся синяя полоса ниже – это чистый капитал агента, а более светлые точки ниже – сделки агента.
Прищурившись, вы можете разглядеть график типа «японская свеча» (используется в техническом анализе, при котором изображают максимальную цену, минимальную цену, цену открытия и цену закрытия), с указанием объемов под ним и странным интерфейсом ниже, похожим на азбуку Морзе, отображающим торговую историю. Похоже, наш агент способен получить достаточные знания из данных в нашем observation_space, так что давайте двигаться дальше. Здесь мы определим наш _next_observation метод, где мы будем масштабировать наблюдаемые данные от 0 до 1.
Важно масштабировать только те данные, которые уже видел агент, чтобы избежать предвзятости.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],
])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size
+ 1):], axis=0)
return obsВыполнение действия
Теперь, когда мы установили наше пространство для наблюдения, пришло время прописать нашу функцию stepfunction и, в свою очередь, выполнить предписанное для агента действие. Всякий раз при self.steps_left == 0 для нашей текущей торговой сессии, мы будет продавать какое-то количество BTC, которое у нас имеется на хранении и вызовем функцию _reset_session(). В противном случае, мы устанавливаем вознаграждение (reward) относительно нашего чистого капитала на текущий момент и, если у нас закончились деньги, задаем только doneTrue.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}Выполнение действие – это просто получение данных о current_price (текущая цена), определение задаваемого действия и либо покупка, либо продажа заданного количества BTC. Давайте быстро пропишем _take_action, чтобы протестировать нашу среду.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += salesНаконец, аналогичным образом мы добавим сделку к self.trades и обновим данные о нашем чистом капитале и историю счета.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)Теперь наши агенты могут инициировать новую среду, проходить через нее и предпринимать действия, влияющие на среду. Пришло время посмотреть, как они будут проводить сделки.
Наблюдение за ботами в действии
Наш метод отображения данных мог бы быть не сложнее вызова функции print(self.net_worth), но это неинтересно. Вместо этого мы построим простой график цен типа «японской свечи» с объемами и отдельный график для нашего чистого капитала.
Мы возьмем код на StockTradingGraph.py из последней статьи, которую я написал, и повторно используем его для визуализации нашей Биткоин-среды. Вы можете взять код с моего Github.
Первое, что мы сделаем, это обновим self.df['Date']everywhere на self.df['Timestamp'] и удалим все вызовы date2num, поскольку наши даты уже поступают в формате метки времени unix. Затем в своем методе отображения данных мы обновим временные метки, чтобы отображались читабельные даты, а не цифры.
from datetime import datetime
Сначала загрузите библиотеку временных зон (datetime library), затем мы воспользуемся методом utcfromtimestamp, чтобы получить строку UTC от каждой метки времени и strftime для перевода этой строки в формат Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime(
'%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])Наконец, мы меняем self.df['Volume'] на self.df['Volume_(BTC)'], чтобы соответствовать нашему набору данных, и теперь готовы двигаться дальше. В своем BitcoinTradingEnv теперь мы можем прописать наш метод отображения данных для отображения графика.
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)И вуаля! Теперь мы можем наблюдать, как наши агенты торгуют биткоинами.
Визуализация через Matplotlib того, как наш агент торгует биткоинами
Зеленые всплывающие тэги представляют собой покупки BTC, а красные - продажи. Белый тэг в правом верхнем углу – это текущий чистый капитал агента, а нижний тэг – текущая цена биткоина. Просто, но изящно. Теперь пришло время обучить нашего агента и посмотреть, сколько денег мы можем заработать!
Время для обучения
Одним из критических замечаний, которые я получил по поводу своей первой статьи, было отсутствие перекрестной проверки, или иными словами разделения данных на обучающий набор и тестовый набор. Это нужно для того, чтобы проверить точность вашей окончательной модели на свежих данных, которые она никогда раньше не видела. Хотя это не было проблематикой той статьи, она определенно прослеживается здесь. Поскольку мы используем данные временных рядов, у нас не так много вариантов, когда дело дойдет до перекрестной проверки.
Например, одна из распространенных форм перекрестной проверки называется K-кратной проверкой, где вы разбиваете данные на равные группы K и одну за другой выделяете группу в качестве тестовой и используете остальные данные в качестве обучающей группы. Однако данные временных рядов сильно зависят от времени, то есть более поздние данные сильно зависят от предыдущих данных. Таким образом, K-кратная проверка не сработает.
То же самое касается и большинства других стратегий перекрестной проверки применительно к данным временных рядов. Таким образом, нам остается просто взять фрагмент полного фрейма данных для использования в качестве обучающего набора от начала фрейма до некоторого произвольного индекса и использовать остальные данные в качестве тестового набора.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]Далее, поскольку наша среда настроена только для обработки одного фрейма данных, мы создадим две среды: одну для обучающих данных и одну для тестовых данных.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df,
commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df,
commission=0, serial=True)])Теперь обучение нашей модели так же просто, как создание агента в нашей среде и вызов model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)Здесь мы используем tensorboard, чтобы мы могли легко визуализировать наш график tensorflow и просмотреть некоторые количественные показатели о наших агентах. Например, вот график дисконтированных вознаграждений многих агентов за 200 000 временных шагов:
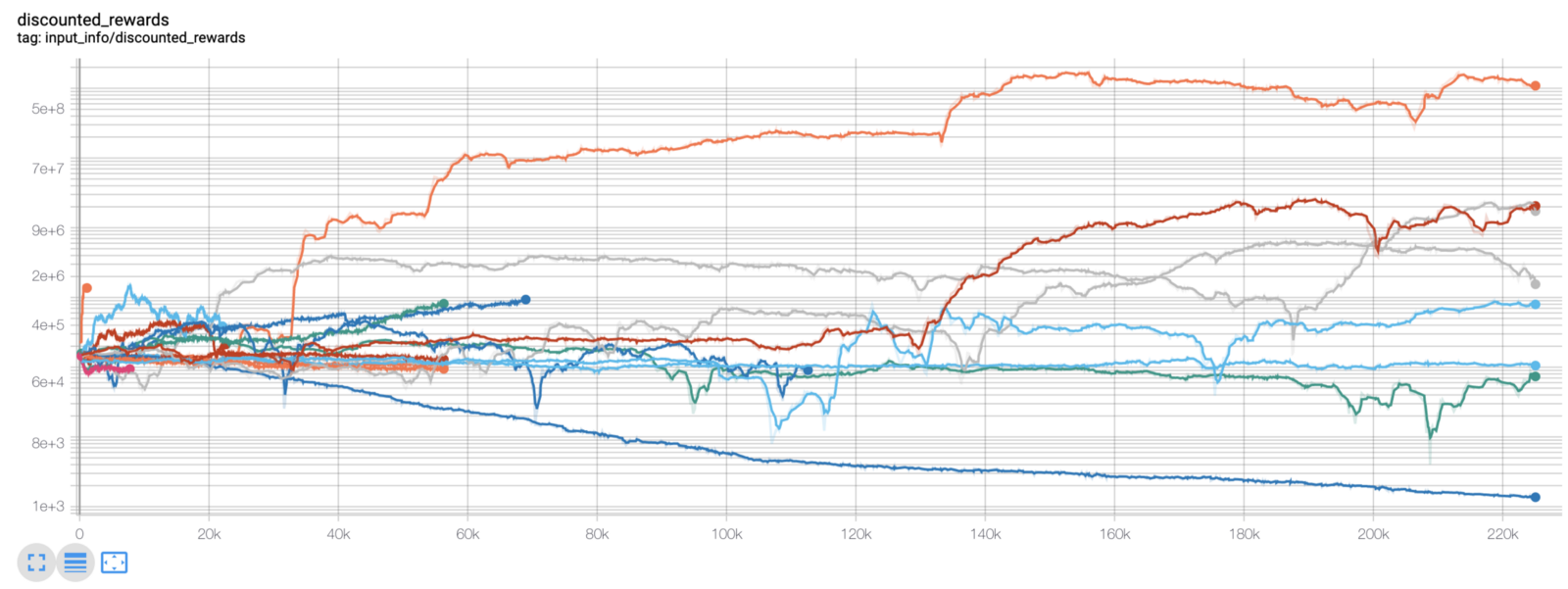
Ух ты, похоже, наши агенты чрезвычайно прибыльны! Наш лучший агент даже сумел в 1000 раз увеличить баланс за 200000 шагов, а остальные в среднем увеличили баланс, минимум, в 30 раз!
Именно в этот момент я понял, что в среде есть ошибка... вот новый график вознаграждений, после исправления этой ошибки:
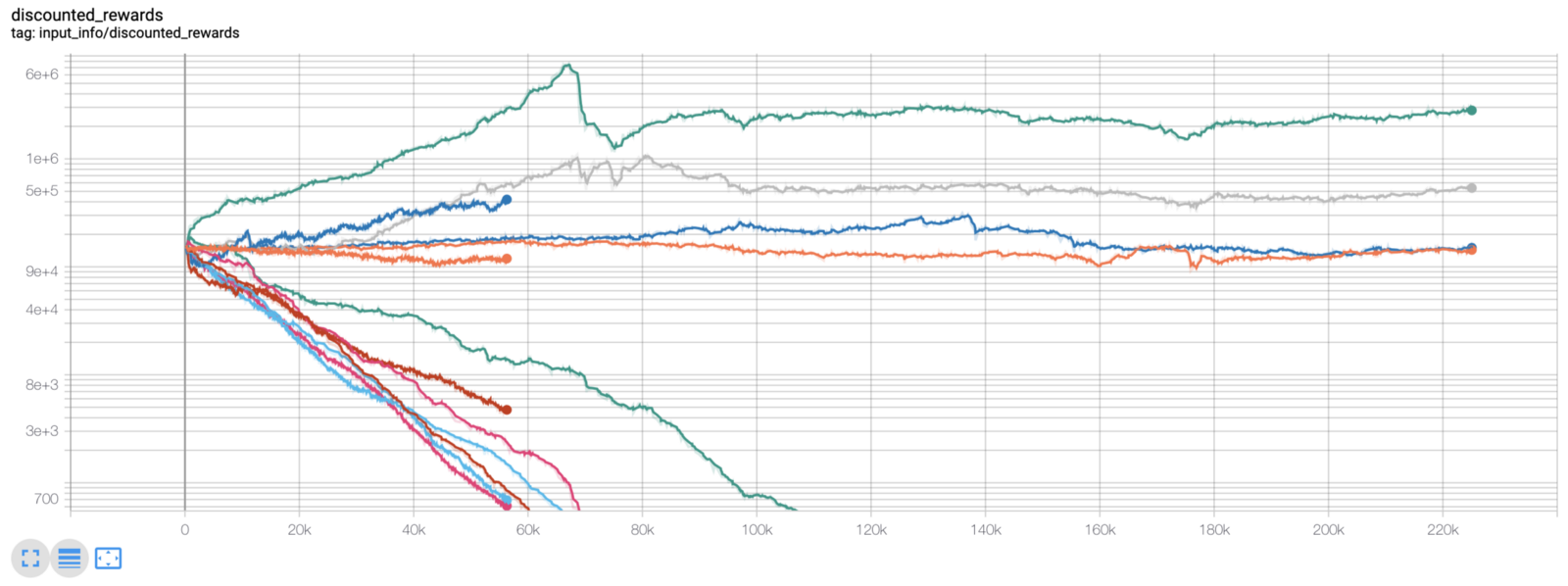
Как видите, парочка наших агентов преуспела, а остальные обанкротились. Однако агенты, которые преуспели, смогли в 10, а то и в 60 раз увеличить свой первоначальный баланс. Я должен признать, что все прибыльные агенты были обучены и протестированы в среде без комиссий, поэтому для нашего агента по-прежнему совершенно нереально зарабатывать реальные деньги. Но мы к чему-то пришли!
Давайте проверим наших агентов в тестовой среде (со свежими данными, которые они никогда не видели раньше), чтобы увидеть, насколько хорошо они научились торговать биткоинами.
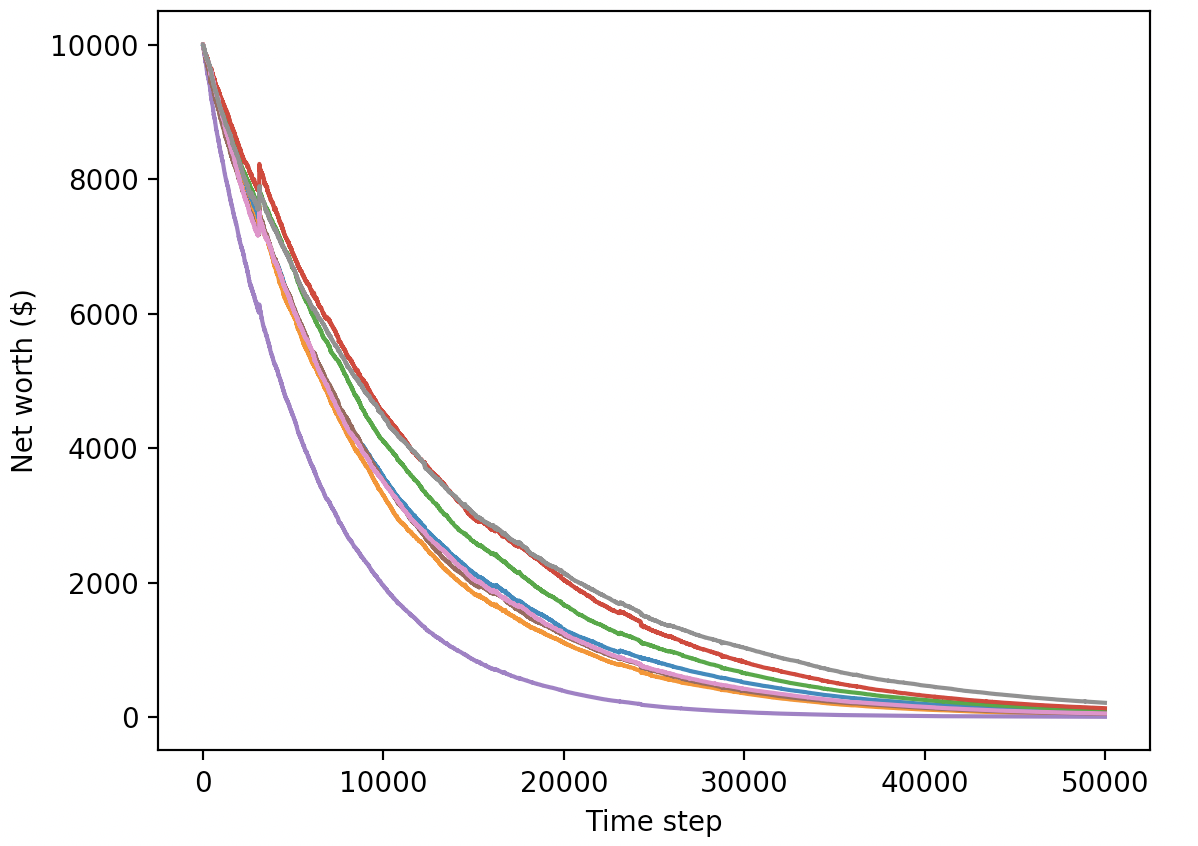
Очевидно, что у нас еще много работы. Если настроить нашу модель на работу с A2C вместо PPO2-агента, мы сможем значительно улучшить работу с этим набором данных. Наконец, мы можем немного откорректировать нашу функцию вознаграждения по совету Шона О'Гормана, т.е. будем вознаграждать за увеличение в размере чистого капитала, а не только за достижение высокого показателя чистого капитала и сохранение его.
reward = self.net_worth - prev_net_worth
Эти два изменения сами по себе значительно улучшают работу на тестовых данных, и, как вы можете видеть ниже, мы, наконец, можем достичь прибыльности на свежих данных, которых не было в обучающем наборе данных.
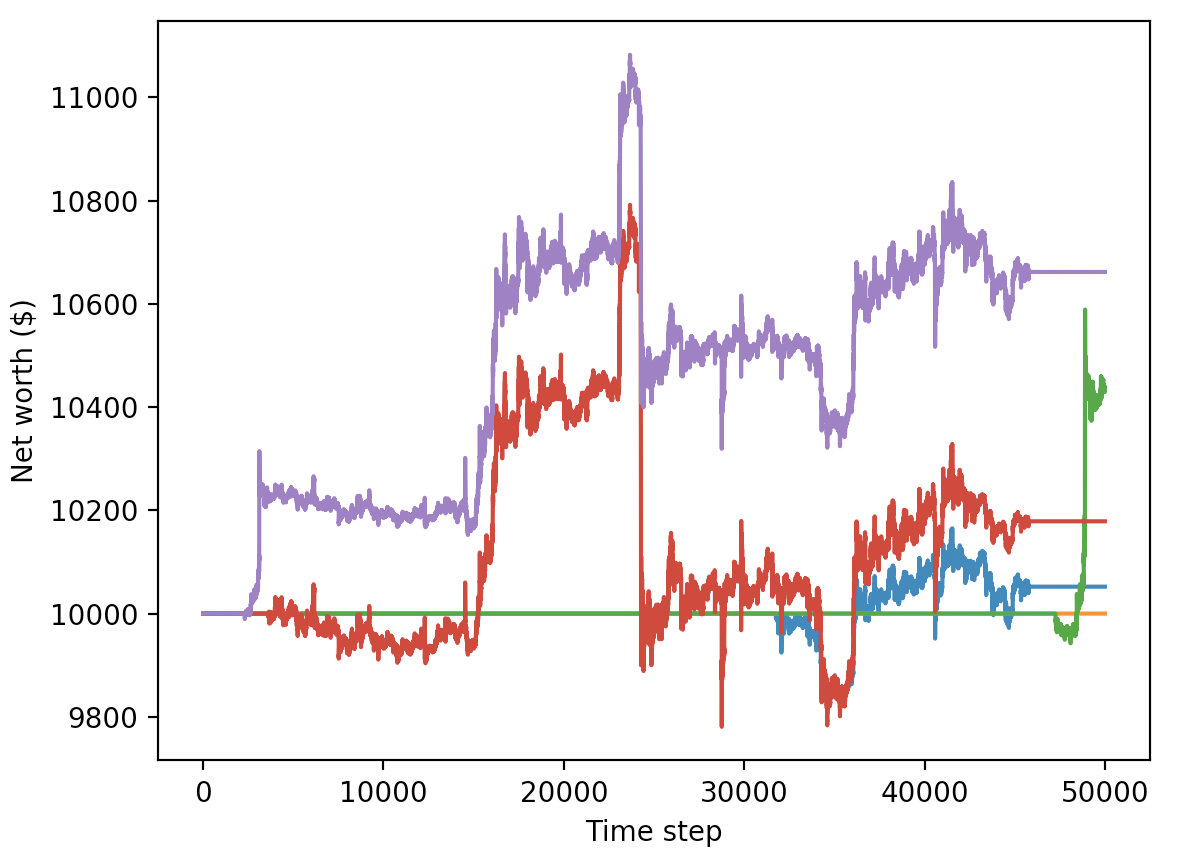
Тем не менее, мы можем еще больше улучшить работу. Для этого нам нужно оптимизировать наши гипер-параметры и обучать наших агентов намного дольше. Самое время настроить GPU и приступить к работе!
Однако эта статья и так получилась несколько растянутой, а у нас все еще имеется масса деталей для проработки, поэтому на этот раз остановимся на этом. В следующей статье мы воспользуемся байесовской оптимизацией для определения наилучших гиперпараметров для нашего проблемного пространства и подготовки среды для обучения/тестирования на графических процессорах с использованием CUDA.
Заключение
Целью этой статьи было создание с нуля агента для прибыльной торговли биткоинами, используя глубокое обучение с подкреплением. Мы смогли выполнить следующее:
- Создать с нуля среду для торговли биткоинами, используя тренажер OpenAI.
- Визуализировать эту среду с помощью Matplotlib.
- Обучить и протестировать наших агентов, используя обычную перекрестную проверку.
- Настроить немного наших агентов на получение прибыли.
Несмотря на то, что наш торговый агент оказался не так выгоден, как мы на это рассчитывали, он определенно движется к цели. В следующий раз мы убедимся в том, что наши агенты постепенно смогут обставить рынок, и мы увидим, как наши торговые боты сделают деньги на живых данных. Следите за моей следующей статьей, и да здравствует Биткоин!