
В настоящее время я работаю над проектом децентрализованного приложения (Shape), первый важный этап разработки которого сейчас приближается к своему завершению. Поскольку затраты на транзакции всегда являются большой проблемой для разработчиков, с помощью этой статьи я хочу поделиться с вами некоторыми идеями, которые пришли мне на ум за последние пару недель/месяцев, касательно этой проблемы с точки зрения оптимизации.

Ниже я приведу список способов оптимизации (некоторые из них будут сопровождаться ссылками на более подробные статьи по теме), которые вы можете применить к дизайну своего контракта. Я начну с более базовых концепций, которые достаточно знакомы публике, а затем по мере повествования перейду к более сложным.
1. Предпочтительные типы данных
Ответить на это можно в нескольких словах: используйте 256-битные переменные, ergo uint256 и bytes32! На первый взгляд это может показаться немного нелогичным, но если вы более тщательно подойдете к осмыслению работы Виртуальной машины Ethereum (EVM), это не покажется лишенным логики. Каждый слот хранения имеет 256 битов. Следовательно, если вы храните только uint8, EVM заполнит все недостающие цифры нулями, а это стоит газа. Кроме того, расчеты также не являются исключениями и выполняются на uint256 с помощью EVM, так что здесь любой тип, кроме uint256, также должен быть преобразован.
Примечание: в целом, вы должны стремиться к доведению ваших переменных к такому размеру, чтобы все слоты хранения были заполнены. В разделе «упаковка переменных в один слот через SOLC» станет более ясно, когда имеет смысл использовать переменные с менее 256 битами.
2. Хранение значений в байт-коде контракта
Сравнительно дешевый способ хранения и чтения информации заключается в непосредственном включении их в байт-код смарт-контракта при его развертывании на блокчейне. Недостатком здесь является то, что значение не может быть впоследствии изменено. Однако расход газа как для загрузки, так и для хранения данных будет значительно сокращен. Существует два возможных способа реализации этого метода:
- Добавьте ключевое слово constant к описанию переменной.
- Пропишите значение переменной (выполните хардкод) там, где собираетесь ее использовать.
uint256 public v1;
uint256 public constant v2;
function calculate() returns (uint256 result) {
return v1 * v2 * 10000
}
Переменная v1 будет частью состояния контракта, в то время как v2 и 1000 – частью байт-кода контракта.
(Чтение v1 выполняется через операцию SLOAD, которая сама по себе стоит 200 единиц газа)
3. Упаковка переменных в один слот через SOLC
Когда вы постоянно храните данные на блокчейне, для этого команда сборки SSTORE выполняется в фоновом режиме. Это самая дорогая команда, стоимость которой составляет 20 000 единиц газа, поэтому мы должны постараться использовать ее как можно реже. Внутри структуры количество выполненных операций SSTORE может быть уменьшено просто за счет переставления переменных, как показано на следующем примере:
struct Data {
uint64 a;
uint64 b;
uint128 c;
uint256 d;
}
Data public data;
constructor(uint64 _a, uint64 _b, uint128 _c, uint256 _d) public {
Data.a = _a;
Data.b = _b;
Data.c = _c;
Data.d = _d;
}Обратите внимание, что внутри структуры все переменные, которые могут в сумме заполнить 256-битный слот, упорядочены таким образом, чтобы компилятор позже мог сложить их вместе (это также работает, если переменные заполняют менее 256 бит). В данном конкретном примере операция SSTORE будет использоваться только дважды: один раз для хранения a, b и c и еще раз для хранения d. То же самое относится и к переменным вне структур. Кроме того, имейте в виду, что экономия от размещения нескольких переменных в одном слоте гораздо более существенная, чем экономия, которая достигается путем заполнения всего слота (Предпочтительные типы данных).
Примечание: Не забудьте активизировать оптимизацию для SOLC.
4. Упаковка переменных в один слот с помощью сборки
Метод такого взаиморасположения переменных с целью сведения операций SSTORE к минимуму также можно применить вручную. Следующий код объединит 4 переменные типа uint64 в один 256-битный слот.
Кодировка: слияние переменных в одно целое.
function encode(uint64 _a, uint64 _b, uint64 _c, uint64 _d) internal pure returns (bytes32 x) {
assembly {
let y := 0
mstore(0x20, _d)
mstore(0x18, _c)
mstore(0x10, _b)
mstore(0x8, _a)
x := mload(0x20)
}
}Для считывания необходима декодировка переменной, которая может быть реализована с помощью этой второй функции.
Декодирование: разбиение переменной на ее изначальные части.
function decode(bytes32 x) internal pure returns (uint64 a, uint64 b, uint64 c, uint64 d) {
assembly {
d := x
mstore(0x18, x)
a := mload(0)
mstore(0x10, x)
b := mload(0)
mstore(0x8, x)
c := mload(0)
}
}Сравнивая расход газа этого метода и того, что приведен выше, вы заметите, что этот метод значительно дешевле по ряду причин:
- Точность: используя этот подход, вы можете делать практически все в плане упаковки битов. Например, если вы уже знаете, что вам не нужен последний бит переменной, вы можете легко выполнить оптимизацию, добавив одну переменную, которую вы используете в связке с 256-битной переменной.
- Разовое считывание: поскольку ваши переменные хранятся вместе в одном слоте, вам нужно будет только выполнить одну операцию загрузки, чтобы получить все переменные. Это особенно полезно, если переменные будут использоваться в связке.
Итак, зачем вообще использовать предыдущий метод? Глядя на оба варианта, становится ясно, что нам также нет смысла проводить считывание с использованием сборки для кодировки и декодировки наших переменных, что, следовательно, делает этот второй подход гораздо более склонным к ошибкам. Кроме того, поскольку мы вынуждены будем использовать функции кодировки и декодировки в каждом конкретном случае, стоимость развертывания также значительно возрастет. Однако, если вам действительно нужно сократить расход газа для ваших функций, то этот метод подойдет! (Чем больше переменных вы упакуете в один слот, тем выше будет ваша экономия по сравнению с другим методом.
5. Объединение параметров функций
По аналогии с тем, как вы можете использовать вышеуказанные функции кодировки и декодировки для оптимизации процесса считывания и хранения данных, вы можете также использовать их для объединения параметров вызываемых функций для того, чтобы уменьшить нагрузку от данных. Несмотря на то, что это приводит к незначительному увеличению стоимости исполнения вашей транзакции, базовая плата будет уменьшена таким образом, что в сумме у вас окажется меньше расходов.
В этой статье сравниваются две вызываемые функции, одна с использованием, а другая без использования этой технологии (бит-уплотнение), и в ней хорошо показано, что на самом деле происходит изнутри.
6. Доказательства Меркла для сокращения нагрузки от хранения
Если в двух словах, доказательство Меркла использует один пласт данных для того, чтобы доказать достоверность гораздо большего количества данных.
Если вы не знакомы с концепцией доказательства Меркла, сначала ознакомьтесь с этой и этой статьями, чтобы иметь общее представление.
Преимущества, которые дают доказательства Меркла, поистине изумительны. Давайте рассмотрим пример:
Предположим, мы хотим сохранить транзакцию от покупки автомобиля, содержащую, скажем, все 32 конфигурации. Создание структуры с 32 переменными, по одной для каждой конфигурации, очень дорого! А вот теперь, как работают доказательства Меркла:
- Во-первых, мы смотрим, какая информация будет запрошена вместе с этим и сгруппируем 32 атрибута соответственно. Предположим, что мы нашли 4 группы, каждая из которых содержит 8 конфигураций, для упрощения задачи.
- Теперь мы создаем хэш для каждой из 4 групп из данных внутри них и снова группируем их в соответствии с предыдущим критерием.
- Мы будем повторять это до тех пор, пока не останется только один хэш: корень дерева Меркла (hash1234).
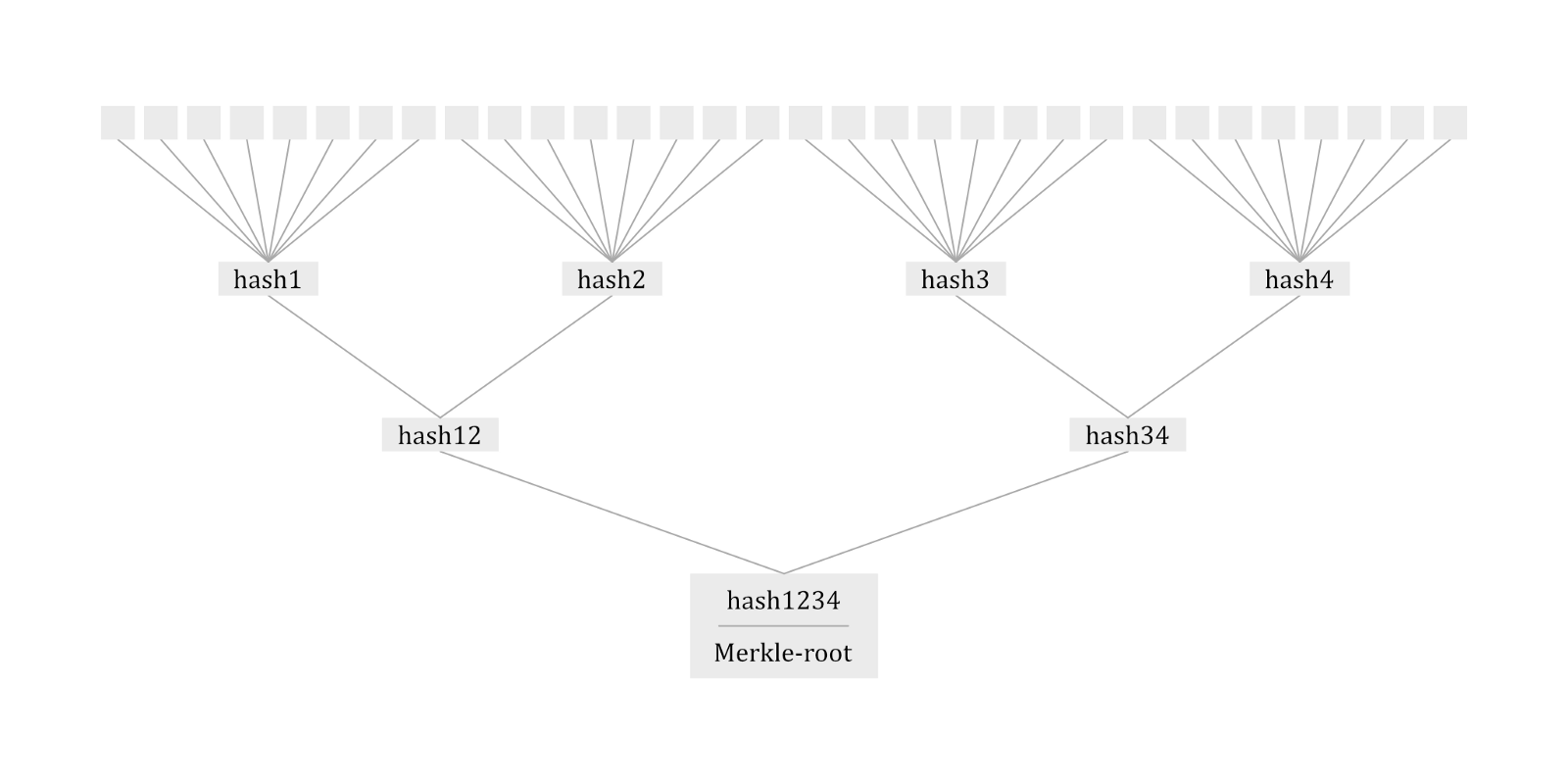
Причина, почему мы их группируем, в зависимости от того, будут ли использоваться два элемента одновременно или нет, заключается в том, что для каждой проверки требуются все элементы этой ветви (выделены цветом на схеме), которые также автоматически проверяются. Это означает, что необходим только один процесс проверки. Например: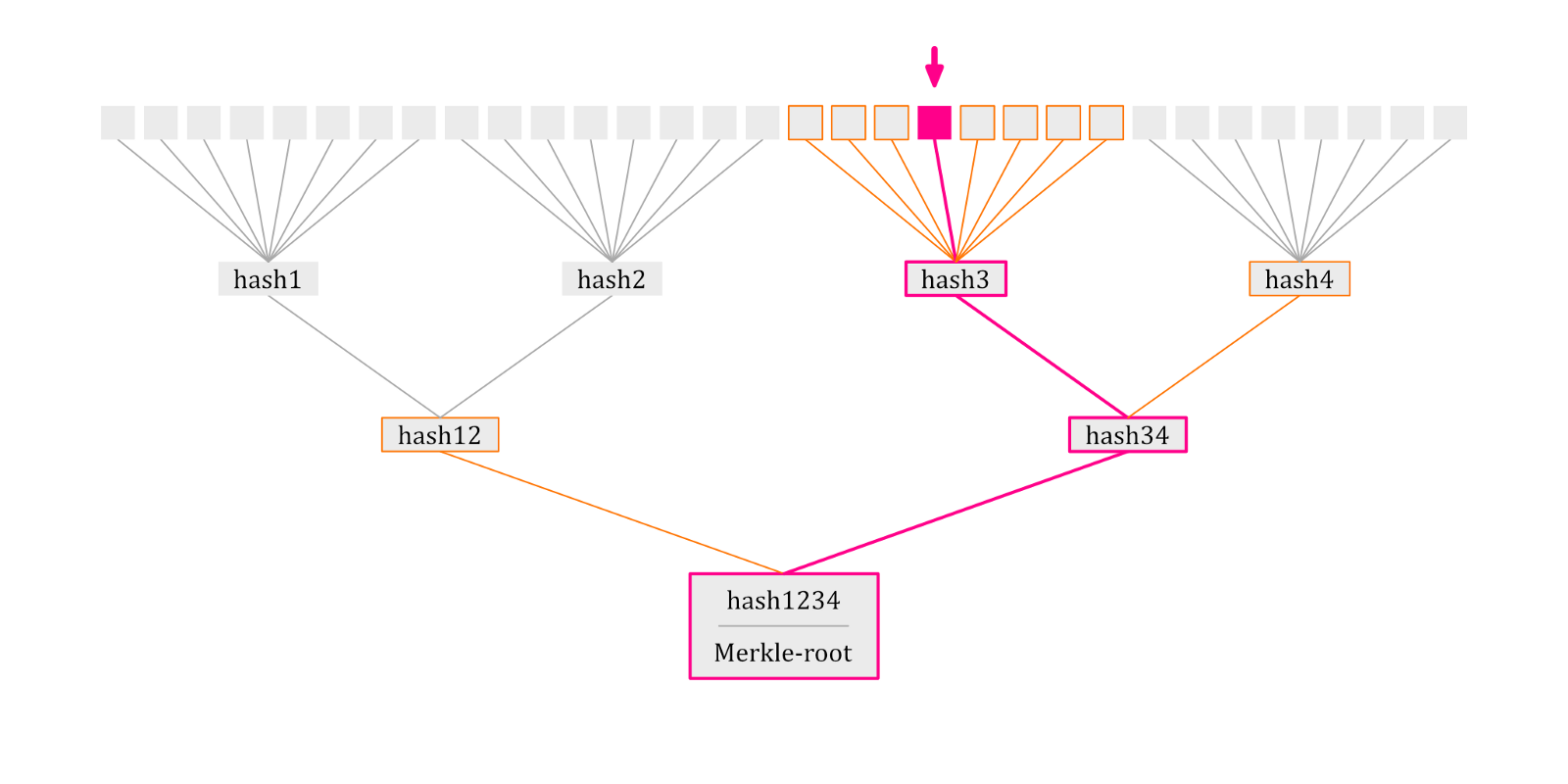
Все, что мы должны были сохранить в цепи здесь, это корень дерева Меркла, обычно переменная из 256 бит (keccak256), и если предположить, что производитель автомобиля отправит вам авто не того цвета, вы сможете легко доказать, что это не тот автомобиль, который вы заказали.
bytes32 public merkleRoot;
//Let a,...,h be the orange base blocks
function check
(
bytes32 hash4,
bytes32 hash12,
uint256 a,
uint32 b,
bytes32 c,
string d,
string e,
bool f,
uint256 g,
uint256 h
)
public view returns (bool success)
{
bytes32 hash3 = keccak256(abi.encodePacked(a, b, c, d, e, f, g, h));
bytes32 hash34 = keccak256(abi.encodePacked(hash3, hash4));
require(keccak256(abi.encodePacked(hash12, hash34)) == merkleRoot, "Wrong Element");
return true;
}Имейте в виду: если к определенной переменной придется обращаться очень часто или ее нужно будет время от времени изменять, возможно логичнее просто сохранить это конкретное значение обычным способом. Кроме того, следите за тем, чтобы ваши ветви не становились слишком большими, потому что в противном случае вы превысите количество слотов стека, доступных для этой транзакции.
7. Контракты без сохранения состояния
Контракты без сохранения состояния пользуются тем, что такие вещи, как данные транзакций и вызовы событий, полностью сохраняются на блокчейне. Поэтому вместо того, чтобы постоянно изменять состояние контракта, все, что вам нужно сделать, это отправить транзакцию и передать значение, которое вы хотите сохранить. Поскольку на операции SSTORE обычно приходится большая часть затрат по сделке, контракты без сохранения состояния будут потреблять только часть газа от того, что потребляют контракты с сохранением состояния. В следующей статье подробно рассказывается о концепции контрактов без сохранения состояния, а также о том, как создать такой контракт и его конечный аналог.
Применяя это к нашему примеру с автомобилем (см. выше), мы бы отправили одну или две транзакции, в зависимости от того, можем ли мы объединить параметры функций или нет (5. Объединение параметров функций), в которую мы передаем 32 конфигурации нашего автомобиля. До тех пор, пока нам нужно только проверить информацию, поступающую извне, это работает нормально и выходит даже немного дешевле, чем доказательство Меркла. Однако, с другой стороны, доступ к этой информации из контракта практически невозможен с этой конструкцией без ущерба для централизации, стоимости или пользовательского опыта.
8. Хранение данных в IPFS
Сеть IPFS – это децентрализованное хранилище данных, где каждый файл идентифицируется не через URL, а через хэш его содержимого. Преимущество здесь заключается в том, что хэш не может быть изменен, следовательно, один конкретный хэш всегда будет указывать на один и тот же файл. Таким образом, мы можем просто транслировать наши данные в сеть IPFS, а затем сохранить соответствующий хэш в нашем контракте для ссылки на информацию позднее. Более подробное объяснение того, как это работает, можно найти в этой статье.
Как и контракты без сохранения состояния, этот метод на самом деле не позволяет использовать данные внутри смарт-контракта (возможно с помощью Оракулов). Тем не менее, если вы ищете возможности хранить большие объемы данных, такие как видео файлы, этот подход, безусловно, является лучшим способом сделать это (кстати, Swarm, другая децентрализованная система хранения, также заслуживает внимания как альтернатива IPFS).
Поскольку случаи использования 6, 7 и 8 довольно похожи, ниже приводится краткая информация о том, когда и что использовать:
- Деревья Меркла: От небольших до средних по величине данных. / Данные могут использоваться внутри контракта. / Изменение данных – довольно сложная задача.
- Контракты без сохранения состояния: От небольших до средних по величине данных. / Данные могут использоваться внутри контракта / Данные можно изменять.
- IPFS: Большие массивы данных. / Использование данных внутри контракта требует достаточно много объема / Изменение данных – довольно сложная задача.
Комментарии:
Собака Шредингера
#
Ну вот, все ждали что новые технологии сделают жизнь легче, а проблемы остались старыми - как меньше платить за газ )))
пт, 01/18/2019 - 10:06
MarcoPolo
#
)) не только легче, но и проще! А почитаешь такие материалы и понимаешь что мало что понятно!)
вс, 01/20/2019 - 13:31