
«Человеческое отношение к неосязаемым вещам переменчиво, но для всего есть предел». - Г. Ф. Лавкрафт

Я уже несколько лет занимаюсь разработкой и написанием кодов для блокчейн-решений на базе Ethereum. Если вы следите за новостями в сообществе, то должны были заметить, что здесь мы все делаем по-другому. Мы одержимы идеей минимализма в кодировании, миримся с нелепыми ограничениями и всегда действуем так, будто результат нашей хаотичной деятельности появится в новостях.
В этой статье я расскажу об одном из тех ограничений, которые являются ключевыми сдерживающими факторами для разработчиков Ethereum, а именно: о размере блока. Помимо неизменности, это чуть ли не самое большое ограничение для развития блокчейна.
В отличие от обычного компьютера, сеть Ethereum вычисляется в блоках, а каждый блок может выполнять ограниченный объем кода. Точный лимит варьируется, но в настоящее время речь идет о 10 миллионах газа (г.). Каждая операция EVM Ethereum имеет разную стоимость газа, но главное, о чем вам нужно помнить: чтение одного элемента данных из хранилища составляет 200 г., а запись одного элемента данных в хранилище – 20 000 г.
Включив математический расчет, вы обнаружите, что один блок может иметь около 50 000 операций чтения, 500 операций записи или комбинацию их двух.
Когда люди говорят о том, что блокчейн является решением для автоматизации бизнеса, они не всегда правильно понимают концепцию. Блокчейн автоматизирует реакции в соответствии с неизменными наборами порядков.
Если я разверну контракт в основной сети Ethereum, то любому, кто отправит мне криптокотика, я «отчеканю» и отправлю криптопесика. Таков порядок: за действием следует детерминированная реакция.
Чего блокчейн Ethereum не делает, так это не запускает алгоритм смарт-контракта, который не заканчивается.
Попробуйте сделать это, и вы получите ужасное сообщение о том, что «газ кончился» (ошибка «out of gas»). Для каждого действия мой смарт-контракт может выдать реакцию стоимостью не более 10 миллионов газа. Это означает, что мы должны использовать наши вычислительные ресурсы экономно или разбить задачи на этапы. Если я хочу распределить дивиденды между акционерами с помощью смарт-контракта, то каждый из них должен будет прийти и попросить о них.
Если я запущу цикл для распределения дивидендов, у меня закончится газ, прежде чем я доберусь до 500-го акционера.
Мне нравится, когда написание кодов для приложений приводит меня к математическим расчетам и основным структурам данных. Это все равно что вернуться в университет. Веселые были времена.
Каковы же эти пределы?
При кодировании смарт-контракта вы должны быть очень осторожны с циклами (loops). Цикл – это прямой путь к ошибке «out of gas», разрушающей ваше приложение.
Но кодировать полностью без циклов тоже неприкольно.
Ключ к кодированию смарт-контрактов с максимальной пользой заключается в том, чтобы проявлять особую осторожность со структурами данных, которые мы используем; знать вычислительные пределы, присущие газовым ограничениям блока, и разбивать работу на отдельные вызовы, когда все остальное терпит неудачу.
Чтобы говорить о вычислительных ограничениях, нам нужно будет воспользоваться О-нотацией. Если вам нужно освежить знания, зайдите на сайт википедии и почитайте о O(1), O(log N) и O(N) – ничто другое нам больше не понадобится на данный момент. Я дам вам подсказку: все смарт-контракты Ethereum должны запускаться в крошечном отрезке Excellent, как показано ниже на графике (выделено зеленым):
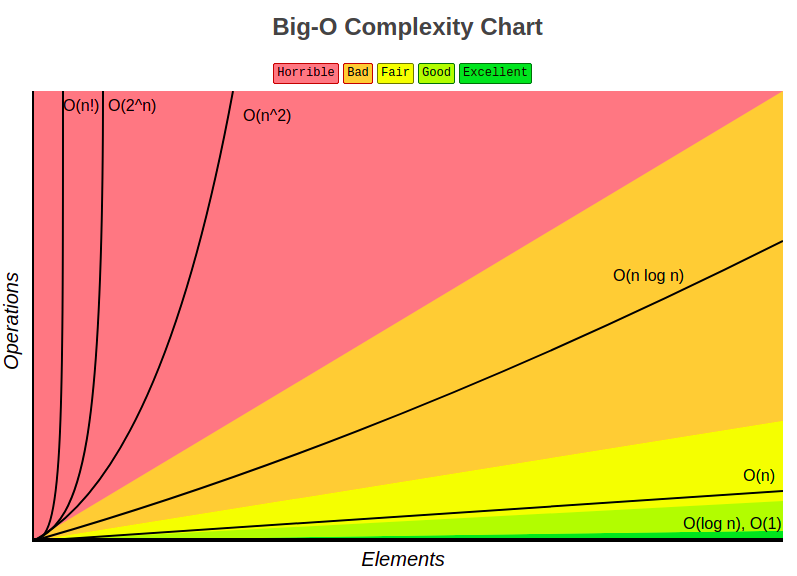
Если мы рассмотрим затраты газа в размере 200 для операции чтения и 20000 для операции записи, а также предел газа на блок в размере 10 миллионов газа, то мы сможем сделать определенные умозаключения об алгоритмах, применяемых в блоке.
Линейные алгоритмы
Основные структуры данных зависят от алгоритмов, которые имеют тенденцию быть O (N). Это, к примеру, подразумевало бы хранение данных в массиве и циклирование через него, чтобы выполнять операции.
Любой алгоритм O (N), считывающий структуру данных, исчерпает газ, если структура данных вырастет примерно до N = 50000. Для простоты допустим, что это включает в себя только одну операцию записи. Мы можем рассматривать это как операцию поиска и записи.
Любой алгоритм O (N), записанный на всех элементах структуры данных, исчерпает газ, если структура данных вырастет примерно до N = 500. Я назову это операцией множественной записи.
Когда объясняешь на реальном примере, все становится более понятным. Если у вас есть токен, который отслеживает всех держателей токенов, и для какой-то операции вам нужно проверить все их перед обновлением одной переменной контракта, то у вас не может быть более 50 000 держателей токенов. Если ваш токен дает вознаграждение держателям токенов и вы обновляете все балансы в одном и том же вызове, то максимальное число держателей токенов составляет около 500.
Логарифмические алгоритмы
Существуют более сложные структуры данных, в которых алгоритмы, управляющие данными, являются O(log N). Это означает, что для поиска определенного значения в структуре данных, содержащей N элементов, вам нужно всего лишь выполнить log N шагов, что является гораздо меньшим числом.
Любой алгоритм O(log2 N), считывающий структуру данных, израсходует газ, если структура данных вырастет примерно до N = 2**50000. Для простоты допустим, что это включает в себя только одну операцию записи. Мы можем рассматривать это как операцию поиска и записи; и это означает, что если ваш алгоритм поиска в структуре данных равен O(log2 N), то ваш смарт-контракт будет масштабироваться. Максимальное число, которое может быть представлено в Solidity, равно 2* * 256, и это также максимальное число элементов, которые можно хранить в любой структуре данных Solidity.
Это означает, что если ваш алгоритм поиска в структуре данных равен O(log2 N), то ваш смарт-контракт будет масштабироваться.
Любой алгоритм O(log2 N), пишущий на структуре данных, не будет писать на всех N элементах структуры данных, максимум он будет делать это на log2 N этих данных. Это означает, что алгоритм O(log2 N) с несколькими записями исчерпает газ, если структура данных вырастет до N = 2**500, что все еще больше, чем максимальное число, которое существует в Solidity.
Это означает, что если ваш алгоритм записи в структуру данных равен O(log2 N), то ваш смарт-контракт будет масштабироваться.
Какой алгоритм использовать?
Мне нравится облегчать жизнь себе и другим. Теперь, когда мы знаем общие пределы и их причины, мы можем «вернуться в университет» и наметить все, что мы можем и не можем сделать:
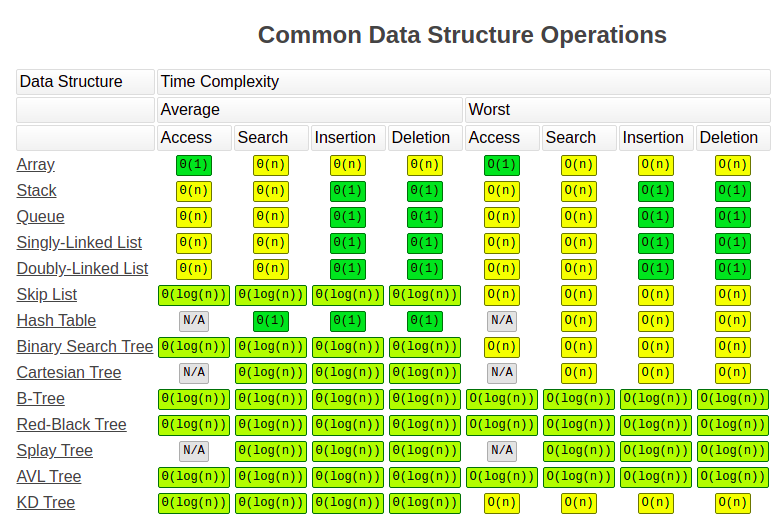
В информатике существует в основном четыре структуры данных:
- Массивы (Arrays);
- Связанные списки (Linked Lists);
- Хэш-таблицы (Hash Tables);
- Деревья (Trees).
Хэш-таблица
Хэш-таблицы представляют собой довольно развитую структуру данных в большинстве вычислительных языков, за исключением языка Solidity. В Solidity все, что относится к хэш-таблице, мы называем мэппингом (mapping). Даже массивы реализованы в виде мэппингов. При реализации связанных списков я использую мэппинги. Когда мэппинги – это все, что у вас есть, то это по сути и все, что вы используете.
Чтение из мэппинга всегда O(1), запись в мэппинг всегда O (1). Тут нет встроенной функции поиска, для этого вам нужно реализовать одну из других структур данных. Все это означает, что вы должны по возможности использовать только мэппинги, и так будет безопасно. Предел размера для мэппинга в Solidity составляет 2* * 256.
Массивы
Массивы – это забавная штука в Solidity, но они также являются единственной встроенной структурой данных, которая может содержать несколько элементов и поддерживает функцию поиска.
Массивы могут содержать 2 * * 256 элементов, если вам не нужно проходить все позиции в одном вызове, и в конце вы только вставляете или удаляете элементы. Если вам нужно проверить все позиции в массиве перед записью в хранилище, вам нужно будет ограничить длину своего массива до примерно 50 тысяч, возможно, и меньше. Массивы следует вставлять только в конце и нигде больше.
Связанные списки
Связанные списки – это ваш выбор структуры данных, когда вам нужно сохранить порядок вставок, а также когда вы хотите вставлять данные в произвольные позиции. Вы можете использовать их для хранения 2 * * 256 элементов, как, например, массивы, для доступа к и произвольной вставки данных. Как и в случае с массивами данных, если вам нужно посетить все позиции в одном вызове, вам нужно ограничить их длину до 50 тысяч элементов.
Вы можете использовать связанные списки, чтобы сохранить элементы данных в определенном порядке, тем самым вставки будут происходить в соответствующей позиции. Такая вставка будет иметь стоимость O(N) чтения и O (1) записи, поэтому она ограничит длину вашего списка до нескольких десятков тысяч без дальнейшей доработки.
Деревья
Деревья – это структура данных, которую вы используете в Solidity, если вам нужно эффективно выполнять поиск в упорядоченном наборе данных. Они сложны, но есть несколько реализаций (дерево порядковой статистики, красно-черное дерево), которые вы можете использовать, если чувствуете себя достаточно продвинутым специалистом. Все операции в дереве имеют сложность O (log N), что означает, что вы можете поддерживать дерево астрономического размера.
Если вы используете дерево для хранения данных, то у вас практически нет ограничений в размере структуры для операций поиска и записи, а также ограничения в тысячу миллионов элементов для операций множественной записи. Тем не менее, вы никогда не сделаете больше, чем несколько сотен операций записи в одном вызове.
Однако использование деревьев имеет свои собственные недостатки. Они сложны для написания и тестирования. Их развертывание сопряжено с большими затратами. На мой взгляд, использование такой сложной структуры данных является огромным риском для вашего проекта.
У вас есть какие-нибудь доказательства всего этого?
Не верьте мне, проверьте сами. Этот небольшой контракт можно использовать для проверки того, сколько операций чтения или записи помещается в блок:
pragma solidity ^0.5.10;contract Gas {
event GasEvent(uint256 data); mapping(uint256 => uint256) public mappingStorage; function writeData(uint256 _times)
public
{
for (uint256 i = 0; i < _times; i++){
mappingStorage[i] = 1;
}
}
function readData(uint256 _times)
public
{
uint256 tmp;
for (uint256 i = 0; i < _times; i++){
tmp = mappingStorage[i];
}
emit GasEvent(_times);
}
}Существуют некоторые дополнительные затраты газа для управления этими циклами и для того, чтобы сделать операцию чтения транзакцией изменения состояния за счет выпуска события, но, как мне кажется, эти функции закончатся после нескольких сотен операций записи или десятков тысяч операций чтения. Вот, что будет, если я ограничу размер блока до 10 миллионов:
Contract: Gas
✓ writeData(100) (484ms)
✓ writeData(200) (888ms)
✓ writeData(300) (1067ms)
✓ writeData(400) (661ms)
x writeData(500) - Out of Gas ✓ readData(10000) (3422ms)
✓ readData(20000) (3372ms)
x readData(30000) - Out of Gas
x readData(40000) - Out of Gas
x readData(50000) - Out of GasБац.
Вывод
Мне потребовалось некоторое время, чтобы наконец понять вычислительные пределы смарт-контрактов. В этой статье я дал четкое и краткое руководство того, что вы можете и не можете сделать в вызове к смарт-контракту Ethereum.
- Все является мэппингом, используйте их всегда, если вам не нужно искать по содержимому.
- Используйте массив, если вам нужно выполнить поиск и вы можете принять вставку и удаление только в конце его.
- Используйте связанные списки, если вам нужно выполнить поиск и вставить данные в произвольные позиции или сохранить упорядоченные данные.
- Используйте дерево, если вам необходимо эффективно выполнять поиск в больших наборах данных.
Для всего остального вам нужно будет разбить свой код на различные вызовы и построить машину состояний. Вам также следует подумать, нужно ли вообще кодировать это в блокчейн.
Если вам нужно посетить все элементы структуры данных, ваш предельный размер составляет несколько десятков тысяч. Если вы должны написать для каждого элемента в структуре данных, то ваш предельный размера будет несколько сотен.
Не тратьте газ!