
Как только стоимость криптовалют начала резко увеличиваться, все больше и больше людей стали предпринимать попытки понять их природу. Сравнительно недавно был отмечен всплеск попыток использовать количественный анализ для исследования криптовалют, что само по себе интересно. Исследователи подумали, что у электронных таблиц есть большой потенциал в прогнозировании криптовалютных тенденций.

Модели, составленные с помощью электронных таблиц, отличаются феноменальной аналитической строгостью. Но, несмотря на это, лучшие фонды мира не используют такой метод в своих методологиях оценки. Зачастую исследователь не понимает, на какой срок он хочет дать прогноз — на 1 неделю, год или 10 лет. Функции, которые используются, часто не дают реального ответа на поставленный вопрос — действительно ли можно понять, какова будет цена криптовалюты, исследуя число пользователей в Telegram? Часто прогнозисты попадают в ловушку: они строят слишком сложные модели и начинают тестирование.
Для иллюстрации своей точки зрения я рассмотрю пример с существующим набором данных и приведу собственный анализ котировок токенов. Для этого мне потребуется немного базовой статистики.
Данные, с которыми нужно работать
Для примера я предлагаю использовать подробную и полную электронную таблицу. В ней есть немало показателей, на основании которых, как кажется на первый взгляд, можно делать хорошие прогнозы. Это активность сообщества, новости, твиты и другие показатели. Большая часть людей, принимая решения, опирается именно на эти показатели или на определенные их комбинации.
Можно написать код для чтения файлов в CSV—формате и представить его в удобном для чтения виде. В нем будут две составляющие: матрица ввода и список чисел, которые нужно “предсказать”.
В нашей таблице 21 столбец и больше 50 строк — обработать такое количество данных одному человеку невозможно. Но для того чтобы делать полезные выводы, мало и этого. В моделях, которые я использовал в прошлом, использовалось больше 10 тысяч образцов. А в базе данных ImageNet, которую используют по всему миру для развития компьютерного зрения, содержится 14 миллионов картинок!
Размерность — главная проблема в обработке данных. Размерность электронной таблицы — это отношение количества строк к числу столбцов. Мы видим, что наша таблица “длинная и тонкая” — в ней много строк, но мало столбцов. Но эта проблема встречается часто: например, в базе данных в Netflix Challenge всего три столбца (фильм, пользователь, рейтинг), и больше 1,4 миллиона строк.
Чем больше столбцов в таблице, тем больше строк в нее нужно добавлять, чтобы полученные результаты вызывали доверие. Мой опыт говорит о том, что строк в таблице должно быть как минимум в 10 раз больше, чем столбцов.
Именно поэтому я рекомендую скептически относиться к выводам, которые сделаны на основе квадратных таблиц — таких, где число столбцов примерно соответствует количеству строк.
Вернемся к примеру, который начали рассматривать выше. 51 строка — хороший показатель. Теперь перейдем к проверке корреляции между парными данными: это нужно для того, чтобы данные стали статистически значимыми.
Смотрим на данные
Здесь очень много графиков и чисел. Если они вам непонятны, переходите сразу к следующему разделу.
Запускаем регрессию. Она выглядит следующим образом:
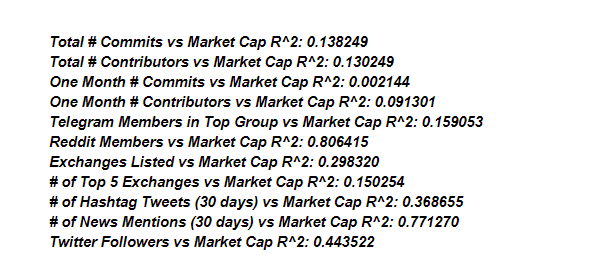
Цифры, расположенные справа — коэффициент детерминации лучшей линии соответствия. Если он не выходит за определенные границы, то можно быть уверенным: существующая линия — самое достоверное предположение о наличии корреляции из возможных.
Давайте рассмотрим несколько конкретных примеров. Например, корреляция между параметрами “Рыночная капитализация” и “Суммарные обязательства” = 0,138249:
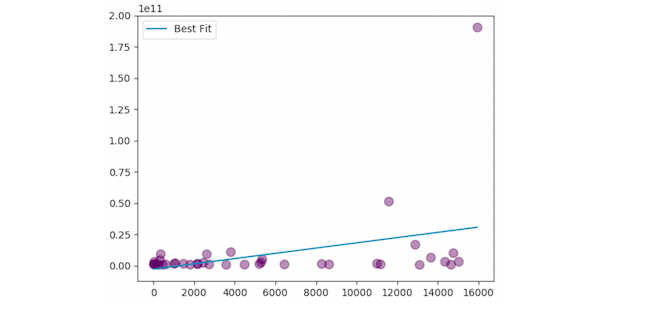
Но нам нужен примерно такой график:
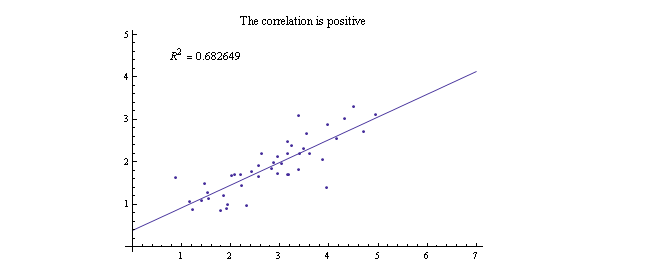
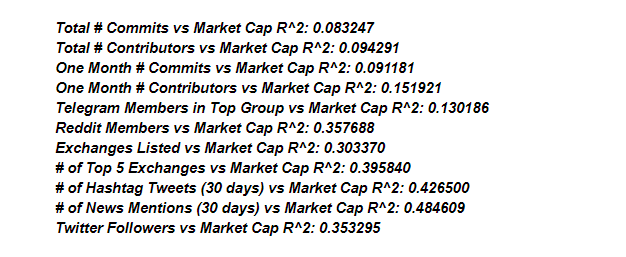
Чем ближе значение R² к единице, тем сильнее корреляция между параметрами. В нашем исследовании есть параметры, которые коррелируют между собой достаточно сильно. Например, это пары “Рыночная капитализация” и “Количество участников на Reddit” (R² = 0,81), “Рыночная капитализация” и “Количество новостей за 30 дней” (R² = 0,77). Ниже вы видите график корреляции между параметрами “Рыночная капитализация” и “Количество участников на Reddit”:
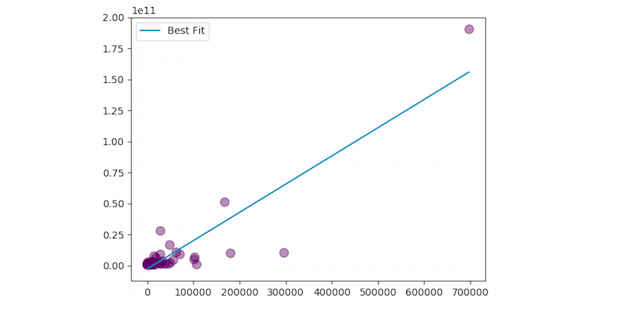
Но и это — не то, что нам нужно. Несмотря на то что значение R² близко к единице, график не того вида, который мы ожидали. Это происходит из—за гетероскедастичности — неоднородности наблюдений, которая возникает из—за того, что дисперсия случайной ошибки в наблюдениях крайне непостоянна. Другими словами, те случайные ошибки, которые всегда есть в исследованиях, оказывают не только очень большое, но и крайне непредсказуемое влияние на результат.
Чтобы избавиться от гетероскедастичности, переведем данные в логарифмический масштаб:
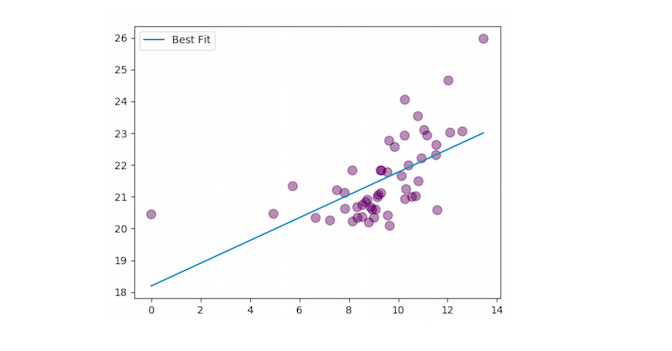
Корреляция получила удар: значение параметра R² для пары “Рыночная капитализация — Количество участников на Reddit” снизилось до 0,36. Но и это неплохой результат. Оскорбляя тех читателей, которые являются почитателями Байеса, можно сказать, что для оценки полученного значения нужно проверить гипотезу о коэффициентах регрессии. Для этого нужно сравнить имеющуюся модель с ситуацией, когда два параметра абсолютно не влияют друг на друга (прямая — горизонтальная линия, значение R² = 0). Если при проверке станет понятно, что параметр “Количество участников на Reddit” делает модель лучше, то мы можем говорить о наличии корреляции в паре “Рыночная капитализация — Количество участников на Reddit”.
Формальной мерой зависимости между двумя параметрами является параметр p. Он получается из F—статистики, которая определяет, с какой вероятностью два параметра связаны между собой. Если значение p близко к нулю, то с уверенностью можно утверждать, что исследуемые параметры взаимосвязаны друг с другом.
В большинстве исследований значения p—параметра — меньше 0,05 или даже 0,01. Судя по всему, рыночная капитализация криптовалюты и ее популярность действительно связаны!
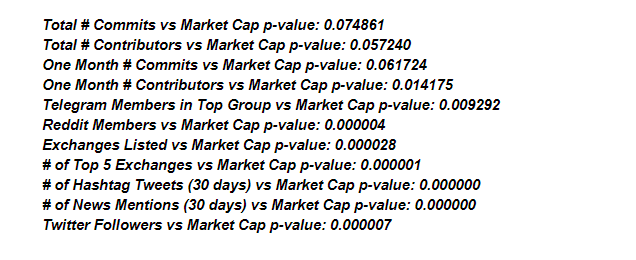
Задумайтесь на секунду. Значения параметра p, возможно, покажут общие тенденции о взаимосвязи между параметрами. Но как это помогает определить, какую криптовалюту купить? Нужно приобретать токены, которые находятся в правом верхнем углу (имеют много участников на Reddit и высокую рыночную капитализацию)? Или лучше покупать криптовалюты, которые находятся выше линии на графике, потому что рыночная капитализация важнее, чем число участников на Reddit?
Мы поговорили о том, как переменные соотносятся друг с другом. Но предсказание курса криптовалют — принципиально иная сфера. Пытаясь угадать, куда двинутся котировки цифровых токенов, нужно понимать, что происходит в реальности. Влияют ли новости на рыночную капитализацию? Или, наоборот, увеличение стоимости криптовалюты влечет за собой новостную активность? Предсказатель криптовалют должен уметь отвечать на эти и другие подобные вопросы.
Здравый смысл подсказывает сделать более быструю проверку. Мы можем не сравнивать факторы, о которых говорили выше, с величиной рыночной капитализации. Мы сравним факторы с тем, насколько изменилась рыночная капитализация. Благо электронная таблица, которая у нас есть, позволяет это сделать.
Если запустить код заново с другими данными, то параметры не так сильно зависят друг от друга:
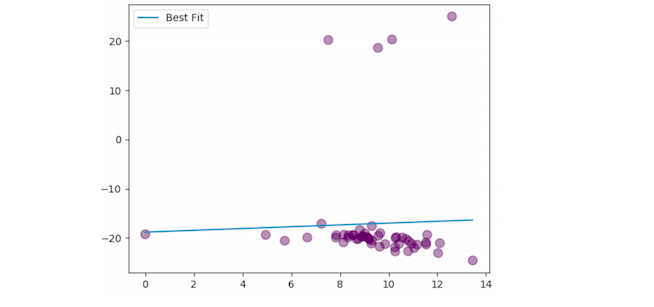
Если убрать изъяны, то результат меняется еще сильнее:
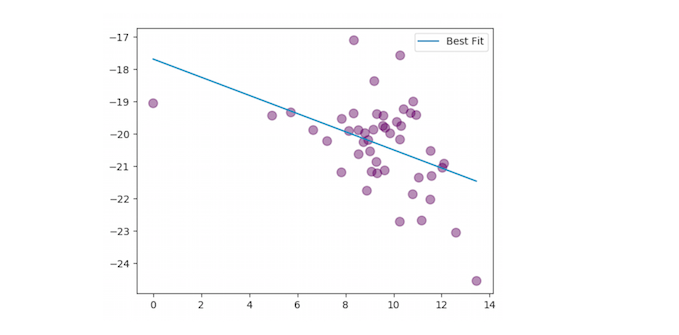
Мы видим отрицательную корреляцию! Видимо, чем больше участников на Reddit, тем ниже капитализация криптовалюты. Мы связываем это по большей части со случайно подобранными данными. Это подтверждают и подобранные окончательно значения p—параметра:

Большинство значений лежат вне тех пределов, при попадании в которые можно было бы говорить о статистической зависимости между двумя параметрами. Это значит, что отношения между параметрами в большей или меньшей степени случайно. Интересно, что между некоторыми параметрами обнаружилась отрицательная корреляция. Например, чем больше подписчиков у проекта в мессенджере Telegram, тем меньше стоит его криптовалюта.
Но единственный вывод, который с уверенностью можно сделать после столь большого текста — это то, что мы не можем делать предсказания, опираясь на имеющиеся у нас данные, пусть даже они и являются достоверными.
И какую модель использовать?
Что же можно сказать в итоге? Можно ли с уверенностью утверждать, что такие параметры, как “Количество участников в Telegram (Reddit)”, не помогут в определении будущей цены криптовалюты?
К сожалению, это так. Не будет ничего хорошего, если вы попытаетесь применять корреляционные модели, основанные на всеобъемлющих и крупных наборах данных. Вы можете попробовать использовать параметр “Изменение количества участников в Telegram” или применить модель с еще большим количеством данных. Но я считаю, что с имеющейся сегодня информацией сложно создать хорошую модель прогнозирования, если не вносить никаких изменений.
Если вы хотите создать такую модель, сначала формализуйте ваши предположения и цели. Убедитесь, что вы можете проверить и верифицировать то, что вы подвергли формализации. Если это удалось — фантастика, вы имеете преимущество! Если нет, попытайтесь заново.
Когда аналитики пытаются понять, сколько будет стоить актив в будущем, они ищут автокорреляции. Есть множество работ по экономике, которые доказывают существование таких моделей, а также одно исследование, в котором это опровергается. На рынках ценных бумаг принято считать, что цены изменяются случайно или по закону Мартингейла. Это значит, что будущие цены акций никак не зависят от того, сколько они стоили раньше.
Существует убеждение, что ситуацию на фондовом рынке предсказать невозможно. Как считают мои друзья-специалисты в квантовых технологиях, в сфере криптовалют ситуация может быть принципиально иной. Здесь есть сигналы, которые могут быть использованы для предсказания цены токенов в будущем — активность в социальных сетях, прошлые котировки. Тем не менее, результаты исследований, которые бы подтверждали возможность прогнозировать курсы криптовалют, основываясь на таких сигналах, сегодня не опубликованы.
Какие выводы можно сделать?
- Данные, которые, как мы думаем, являются очень важными, в реальности имеют намного меньшую значимость.
- Если думать, что у нас есть хорошие модели и стратегии, можно легко себя обмануть. Зачастую аналитики пытаются найти шаблоны, которых нет на самом деле. Но этого можно избежать, если хорошо анализировать данные.
- Количественный анализ сложен для понимания. Корреляции — это лишь первый его этап. Но если мы действительно пытаемся предсказать будущую цену актива, то впереди очень много работы.
Предоставляю ссылку на код, как и обещал в начале статьи. Изучите его и дайте знать, если в нем есть ошибки.